If you are new to SQL Server, you might wonder what an index is and why it’s important. Indexes are crucial for improving query performance and are essential for efficient data retrieval.
In this article, we will discuss the differences between clustered and non-clustered indexes in SQL Server.
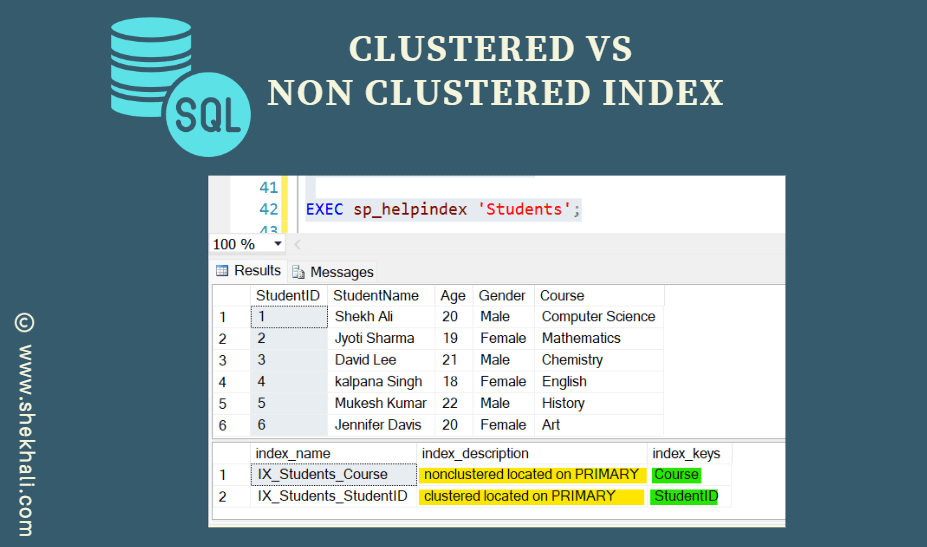
Table of Contents
- 1 What is an Index?
- 2 What is a Clustered index?
- 3 What is a Non clustered index?
- 4 Comparison Table: Clustered vs Non Clustered Index
- 5 How to Create Clustered and Non-Clustered Index in SQL Server?
- 6 How to find which indexes are created on the table?
- 7 When to Use a Clustered or Non-Clustered Index?
- 8 Advantages of Clustered Index
- 9 Advantages of Non Clustered Index.
- 10 Disadvantages of Clustered and Non-Clustered Index.
- 11 Indexing Best Practices
- 12 FAQs
- 12.1 Q: What is the main difference between clustered and non-clustered indexes?
- 12.2 Q: When should you use a clustered index?
- 12.3 Q: When should you use a non-clustered index?
- 12.4 Q: Can a table have both clustered and non-clustered indexes?
- 12.5 Q: Does creating an index improve the performance of SQL queries?
- 12.6 Q: How can I determine which indexes are created on a table?
- 12.7 Q: Can I create a clustered index on a column that already has a non-clustered index?
- 12.8 Q: Can you create a non-clustered index on a column that already has a clustered index?
- 12.9 Q: What are composite indexes?
- 12.10 Q: Can you create a composite clustered index?
- 12.11 Related
What is an Index?
In SQL Server, an index is an object that is used to speed up the data retrieval process by allowing queries to locate data in a table quickly. Think of it as a roadmap for your data, where each index entry contains a value and a pointer to the location of the corresponding row.
Indexes can be created on one or more columns of a table, and they can be either clustered or non-clustered.
What is a Clustered index?
A clustered index is used to sort and store the data in a table based on the index key values.
In other words, A clustered index is a type of database index that determines the physical order of data rows within a table. This means that the data in the table is physically stored on disk in the same order as the clustered index key.
- A table can have only one clustered index, which defines the table data alphabetically, just like a dictionary.
- A clustered index is usually created on a primary key or a column with unique values.
What is a Non clustered index?
In SQL Server, a non-clustered index is a database structure that enhances data retrieval speed from a table. It creates a separate data structure that stores index key values and pointers to the actual data rows within a table. Non-clustered indexes are like a phone book where you can look up data based on the values of the index.
- A table can have multiple non-clustered indexes, but the data in the table remains unsorted.
- Unlike clustered indexes, non-clustered indexes don’t dictate the physical order of data rows in the table. Still, they enhance query performance by allowing efficient data retrieval based on the indexed columns.
Explanation:
Think of a non-clustered index like the index at the back of a book. You don’t read every page from the start when you want to find information in a book quickly. Instead, you go to the index, find the page number where the topic you’re interested in is mentioned, and then flip to that page.
In SQL Server, a non-clustered index is like that index in the book. It’s a separate list that keeps track of key information (like the words in an index and their page numbers) to help you find data in a table faster.
Instead of scanning the entire table, which can be like reading the entire book, SQL Server uses this index to pinpoint where the data you’re looking for is stored. This makes searching for data in a large table much quicker and more efficient.
Unlike a clustered index, which rearranges the physical order of the book’s pages, a non-clustered index doesn’t change how the data is physically stored in the table. It’s just a mechanism that helps you find things faster, like an index in a book without reordering the pages.
Comparison Table: Clustered vs Non Clustered Index
Here is a comparison table to help you understand the differences between clustered and non-clustered indexes:
| Parameters | Clustered Index | Non-Clustered Index |
|---|---|---|
| Definition: | A Clustered index determines the physical order of data in a table based on the indexed column(s). | A non-clustered index stores a separate data structure to locate the row(s) that match the indexed column(s) within a table. |
| Data structure: | The clustered index data is physically sorted on disk based on the index key. | The non-clustered index contains the index key and a pointer to the actual data row within a table. |
| Number of indexes: | Only one clustered index is allowed per table. | A table can have multiple non-clustered indexes. |
| Index key columns: | It can be created on one column per table. | It can be created on one or more columns per table. |
| Index key uniqueness: | Clustered Index column must be unique. | It can be non-unique. |
| Index data: | It contains all columns of the table. | It contains only the indexed columns and a pointer to the data row. |
| Query performance: | It provides fast retrieval of data for range-based queries and full table scans. Generally performs better on range queries, as the data is physically sorted. | Generally performs better on single-row lookups, as the data is not physically sorted. |
| Insert/Update/Delete performance: | Slower than non-clustered index as it involves moving data physically on disk. | Faster than clustered index as it does not involve data movement. |
| Disk space: | Clustered index requires more disk space than non-clustered indexes as it stores actual data on disk. | It requires less disk space than clustered indexes, as only the indexed columns and a pointer to the data row are stored. |
| Primary key constraint: | Can be used to enforce a primary key constraint. | Cannot be used to enforce a primary key constraint. |
| Suitable for: | Large tables with range-based queries. | Small tables or tables with frequent updates/deletes. |
| Examples: | CustomerID in the Customer table. | LastName in the Employee table and PostalCode in the Address table. |
| Script for creating: | CREATE CLUSTERED INDEX idx_customerid ON Customer(CustomerID); | CREATE NONCLUSTERED INDEX idx_lastname ON Employee(LastName); |
How to Create Clustered and Non-Clustered Index in SQL Server?
Here are some examples of clustered and non-clustered indexes in SQL Server.
Example of Clustered Index:
Consider a table named Students. The table contains the following columns: StudentID, StudentName, Age, Gender, and Course.
Here, StudentID is the primary key column.
-- Creating Students Table
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
StudentName VARCHAR(50),
Age INT,
Gender VARCHAR(10),
Course VARCHAR(50)
);
-- Inserting records into Students Table
INSERT INTO Students (StudentID, StudentName, Age, Gender, Course)
VALUES (1, 'Shekh Ali', 20, 'Male', 'Computer Science'),
(2, 'Jyoti Sharma', 19, 'Female', 'Mathematics'),
(3, 'David Lee', 21, 'Male', 'Chemistry'),
(4, 'kalpana Singh', 18, 'Female', 'English'),
(5, 'Mukesh Kumar', 22, 'Male', 'History'),
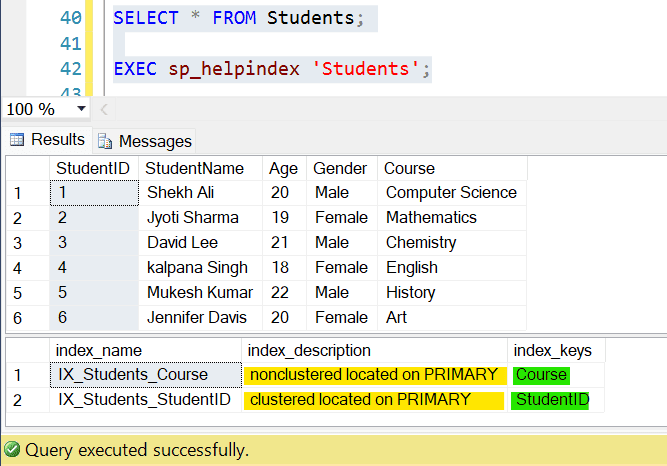
(6, 'Jennifer Davis', 20, 'Female', 'Art');Once you run the above SQL Query, the ‘Students’ table will look like this:
| StudentID | StudentName | Age | Gender | Course |
|---|---|---|---|---|
| 1 | Shekh Ali | 20 | Male | Computer Science |
| 2 | Jyoti Sharma | 19 | Female | Mathematics |
| 3 | David Lee | 21 | Male | Chemistry |
| 4 | kalpana Singh | 18 | Female | English |
| 5 | Mukesh Kumar | 22 | Male | History |
| 6 | Jennifer Davis | 20 | Female | Art |
To create a clustered index on the StudentID column, we can use the following SQL query:
-- Creating a clustered index on the 'StudentID' column
CREATE CLUSTERED INDEX IX_Students_StudentID ON Students(StudentID);
Note: If you have a primary key column in the table, then a Clustered Index will be created on that column by default. Creating a clustered index on the same column might throw an error like this.
“Cannot create more than one clustered index on table ‘Students’. Drop the existing clustered index ‘PK__Students__32C52A79C3C6D85B’ before creating another.”
So, First we need to drop the existing clustered index before creating the new one. Here is the SQL Query.
-- Drop the existing clustered index on the 'StudentID' column
ALTER TABLE Students
DROP CONSTRAINT PK__Students__32C52A79C3C6D85B
-- Create a new clustered index on the 'StudentID' column
CREATE CLUSTERED INDEX IX_Students_StudentID ON Students(StudentID)The above SQL query will create a clustered index on the ‘StudentID’ column, which will be used to physically order the data in the table based on the values in the ‘StudentID’ column.
Example of Non-Clustered Index:
Consider the same table ‘Students’. If we want to create a non-clustered index on the ‘Course’ column, we can use the following SQL query:
-- Creating a non-clustered index on the 'Course' column.
CREATE NONCLUSTERED INDEX IX_Students_Course ON Students(Course);The above SQL query will create a non-clustered index on the ‘Course’ column, which will be used to create a separate data structure that stores the values of the ‘Course’ column along with reference to the location of the corresponding row in the table.
By creating non-clustered indexes on frequently used columns, we can improve the performance of queries that search for data based on those columns.
How to find which indexes are created on the table?
We can use the following SQL query to find out which indexes are created on a particular table:
Syntax:
EXEC sp_helpindex 'TableName';
Here, ‘TableName’ is the name of the table for which we want to see the list of indexes.
Once we run the above SQL query, we can see the Clustered index is created on the StudentID column, and the Non-Clustered index is created on the Course column of the Customers table.
When to Use a Clustered or Non-Clustered Index?
Clustered indexes should be used when we want to improve the performance of queries that retrieve a range of values from a table based on the primary key column or a column with unique values.
Non-clustered indexes should be used when we want to improve the performance of queries that search for data based on frequently used columns other than the primary key column.
Advantages of Clustered Index
The following are some of the advantages of using a clustered index in a SQL Server:
- Faster Data Retrieval: Clustered indexes store data in a sorted manner, allowing for faster data retrieval. When a query is executed against a table with a clustered index, SQL Server uses the Index to quickly locate the required data, resulting in faster query performance.
- Avoidance of Table Scans: Since data in a clustered index is sorted, SQL Server can quickly skip over large portions of the table that do not contain the data being searched for. This avoids the need for a table scan, which can be time-consuming and resource-intensive.
- Improved Data Locality: Clustered indexes store data in the same order as the Index, which can improve data locality. That means the data is stored physically close to related data, resulting in faster retrieval and improved performance.
- Clustered Index is the Primary Key: When a table has a clustered index, the Index is also the primary key. It ensures that each row in the table is uniquely identified, making it easier to maintain referential integrity.
- Efficient Data Modification: When data is added or modified in a table with a clustered index, SQL Server only needs to update the Index and the affected data pages. It makes modifications more efficient than with non-clustered indexes.
Overall, using a clustered index can result in faster query performance and more efficient data retrieval, making it a popular choice for improving the performance of SQL Server databases.
Advantages of Non Clustered Index.
The following are some of the advantages of using a non-clustered index in a SQL Server:
- Multiple Indexes per Table: A clustered index can be only one in a table, but a table can have multiple non-clustered indexes. It allows for more flexible indexing strategies, enabling the optimization of specific queries.
- Faster Query Performance: Non-clustered indexes allow SQL Server to quickly locate data based on the columns included in the index. It can improve query performance, particularly when searching for data not covered by a clustered index.
- Reduced Disk Space Usage: Non-clustered indexes typically require less disk space than clustered indexes since they do not store the actual data. It can be particularly beneficial when working with large tables.
- Efficient Sorting: Non-clustered indexes can be used to sort data based on the indexed columns. It can be particularly beneficial when working with large datasets, as sorting can be time-consuming.
- Covering Indexes: Non-clustered indexes can be used as covering indexes, meaning that all of the columns required by a query are included in the index. It can significantly improve query performance since SQL Server does not need to access the actual data pages.
Overall, non-clustered indexes can improve query performance, reduce disk space usage, and offer more flexible indexing strategies than clustered indexes.
However, they may not be as efficient as clustered indexes for retrieving large amounts of data since they require more disk I/O.
Disadvantages of Clustered and Non-Clustered Index.
There are certain disadvantages to both clustered and non-clustered indexes in SQL Server:
Disadvantages of Clustered Index:
- Slower Write Performance: SQL Server must adjust the index to maintain the sort order since the data in a clustered index is physically sorted when a new row is inserted, or an existing row is updated. It can lead to slower write performance compared to non-clustered indexes.
- Limited Number of Clustered Indexes per Table: SQL Server allows only one clustered index per table. If you need to sort the data in multiple ways, you may need to create multiple tables or use non-clustered indexes.
- Disk Space Usage: Clustered indexes can use more disk space than non-clustered indexes since they store the actual data. Itis can be particularly problematic when working with large tables.
Disadvantages of Non-clustered Index:
- Slower Query Performance: Although non-clustered indexes can improve query performance, they can be slower than clustered indexes when retrieving large amounts of data. This is because non-clustered indexes require more disk I/O to retrieve data.
- More Disk Space Usage: Although non-clustered indexes typically require less disk space than clustered indexes, they can still consume a significant amount of disk space when working with large tables.
- Additional Maintenance Overhead: Since non-clustered indexes are separate from the actual data, they require additional maintenance overhead to keep them synchronized with the data.
Overall, both clustered and non-clustered indexes have their advantages and disadvantages. The choice of which index to use depends on the specific needs of the application and the nature of the data being stored.
Indexing Best Practices
Indexing is a critical aspect of database design, and it is essential to follow some best practices to ensure optimal database performance. Here are some of the best practices for indexing in SQL Server:
- Identify the columns that need indexing: Not all columns in a table require indexing, and indexing every column can lead to performance issues. Identify the columns frequently used in queries and crucial for database performance. These columns should be indexed.
- Choose the appropriate index type: As discussed earlier, SQL Server offers different types of indexes, such as clustered, non-clustered, and full-text indexes. Choose the appropriate index type based on the requirements of the database.
- Use index filters: Index filters can help reduce the size of the index and improve query performance. Index filters are conditions that limit the number of rows that are included in an index.
- Keep indexes updated: Indexes should be kept up-to-date to ensure optimal database performance. Indexes should be rebuilt or reorganized periodically to maintain optimal performance.
- Be careful when dropping indexes: Dropping an index can significantly impact database performance. Before dropping an index, make sure to identify any queries that use the index and determine if the index is no longer needed.
References: MSDN-Clustered vs Non Clustered Index
By following these best practices, you can ensure the optimal performance of your SQL Server database.
FAQs
Here are some frequently asked questions (FAQs) related to clustered and non-clustered indexes in SQL Server:
Q: What is the main difference between clustered and non-clustered indexes?
The main difference between clustered and non-clustered indexes is that a table can have only one clustered index, which determines the physical order of data in the table, while it can have multiple non-clustered indexes that don’t affect the physical order of data.
Q: When should you use a clustered index?
It would be best to use a clustered index when you frequently search for data based on a range of values in a specific column or when you need to order the data in the table based on a specific column.
Q: When should you use a non-clustered index?
It would be best to use a non-clustered index when you frequently search for data based on a specific column or a combination of columns or when you need to join two or more tables based on a specific column or column.
Q: Can a table have both clustered and non-clustered indexes?
Yes, a table can have both clustered and non-clustered indexes, but it can have only one clustered index.
Q: Does creating an index improve the performance of SQL queries?
Yes, creating an index can improve the performance of SQL queries that involve searching, sorting, or joining data in a table.
However, creating too many indexes or creating indexes on columns that are rarely used can also have a negative impact on query performance.
Q: How can I determine which indexes are created on a table?
You can use the SQL Server Management Studio (SSMS) or the Transact-SQL (T-SQL) command sp_helpindex to determine which indexes are created on a table.
Q: Can I create a clustered index on a column that already has a non-clustered index?
Yes, you can create a clustered index on a column that already has a non-clustered index, but you need to drop the non-clustered index first.
Q: Can you create a non-clustered index on a column that already has a clustered index?
Yes, you can create a non-clustered index on a column that already has a clustered index. However, you must be careful to avoid creating too many non-clustered indexes, as they can slow down insert, update, and delete operations.
Q: What are composite indexes?
Composite indexes are indexes that are created on two or more columns in a table instead of just one column. Composite indexes can improve the performance of queries that involve searching, sorting, or joining data based on multiple columns.
Q: Can you create a composite clustered index?
Yes, you can create a composite clustered index on two or more columns in a table, but the columns must be in a specific order, and the order cannot be changed after the index is created.
You might want to read this too:
- Mastering Database Normalization: Best Practices and Techniques
- Mastering SQL Inner Join
- Understanding CRM Databases
- Types of Joins in SQL Server
- Having VS Where Clause in SQL
- SQL EXISTS – Exploring EXISTS Operator in SQL Server
- Like operator in SQL
- Different ways to delete duplicate rows in SQL Server
- COALESCE in SQL With Examples and Use Cases for Handling NULL Values
- SQL Server CONVERT Function: How to Convert Data Types in SQL Server
- Delete vs Truncate vs Drop in SQL Server
- SQL Server TRY_CAST() Function – Understanding TRY_CAST() in SQL with [Examples]
- SQL Server Try Catch: Error Handling in SQL Server With [Examples]

- C# 12 New Features in 2025: What’s New with .NET 8 - April 11, 2025
- Difference Between WCF and Web API with Examples: A Comprehensive Guide - March 27, 2025
- PUT vs PATCH vs POST in REST API: Key Differences Explained With Examples - March 23, 2025