Database normalization is a technique used to organize data in a relational database. It involves breaking down a large table into smaller tables and defining relationships between them. The normalization goal is to eliminate redundant data and ensure that each piece of information is stored in only one place.
Relational databases are the backbone of many software systems. They allow us to store, manage, and retrieve data in an organized and efficient way. However, as the size and complexity of our data grow, so do the challenges of maintaining its integrity and consistency. This is where database normalization comes in.
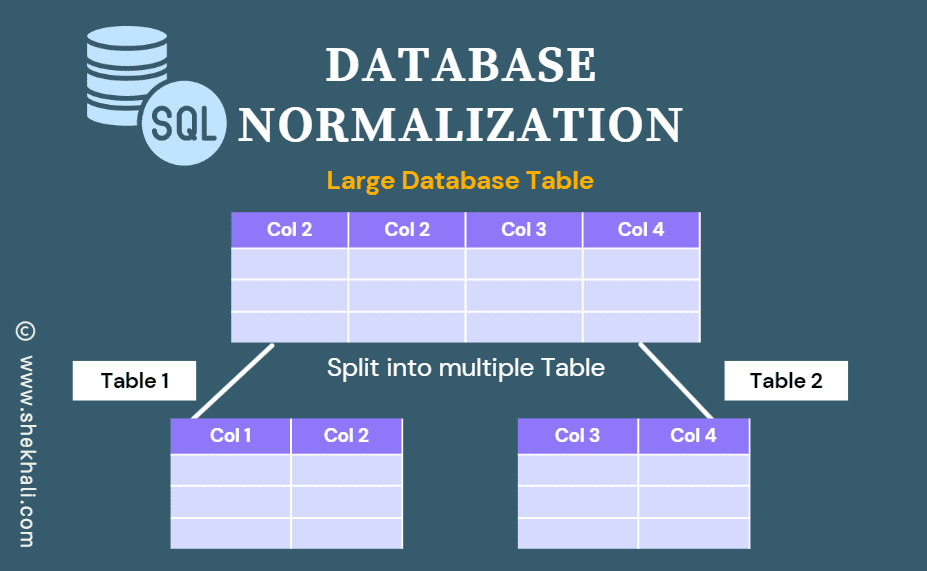
Normalizing a database can improve data integrity and reduce data anomalies.
In this article, we’ll discuss what normalization is, the various normal forms in SQL, the problems that can arise without normalization, and how normalization improves the performance of relational databases.
Table of Contents
- 1 What Is Normalization in Database?
- 2 List of Normal Forms in SQL
- 3 Problems Without Using Database Normalization
- 4 Example: Database Normalization
- 5 First Normal Form (1NF)
- 6 Second Normal Form (2NF)
- 7 Third Normal Form (3NF)
- 8 Candidate key
- 9 primary key
- 10 Fourth Normal Form (4NF)
- 11 How does data normalization improve the performance of relational databases?
- 12 FAQs:
- 12.1 Q: What is Database Normalization?
- 12.2 Q: Why is database normalization necessary?
- 12.3 Q: What are the different normal forms in database normalization?
- 12.4 Q: What is the purpose of each normal form?
- 12.5 Q: How does normalization improve database performance?
- 12.6 Q: Is normalization always necessary?
- 12.7 Related
What Is Normalization in Database?
Database normalization is the process of organizing data in a database to minimize redundancy and dependency.
The goal is to ensure that each piece of data is stored in one place and in one format. This improves data integrity, eliminates data duplication, and simplifies data management.
Normalization is achieved by breaking down a larger table into smaller tables and establishing relationships between them. Relationships are defined between tables using foreign keys.
This process is called normalization because it brings the data to a “normal” form that is easier to work with and maintain.
Normalization is also essential for properly functioning database operations, including queries and joins.
List of Normal Forms in SQL
There are several normal forms in SQL, each with its own set of rules. The most common normal forms are:
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
- Boyce and Codd Normal Form (BCNF)
- Fourth Normal Form (4NF)
Problems Without Using Database Normalization
A database not being normalized correctly can lead to data anomalies. Three types of anomalies can occur insertion, updation, and deletion.
01. Insertion Anomaly
An Insertion anomaly occurs when you can’t add data to a table without adding unrelated data. For example, imagine you have a table that contains customer orders. If you don’t normalize the data, you might include the customer’s address in the same table. It means you can’t add an order for a new customer without their address, even if you don’t have that information yet.
02. Updation Anomaly
An Updation anomaly occurs when you have to update the same data in multiple places. For example, imagine you have a table that contains customer orders. If you don’t normalize the data, you might include the customer’s name and address in the same table. If a customer moves, you must update their address in every order they’ve placed.
03. Deletion Anomaly
A deletion anomaly occurs when you delete data from a table and unintentionally delete other data as well.
Specifically, deletion anomaly occurs when a row of data is deleted from a table containing the information required by other tables in the database. This can result in the loss of information that is necessary for the other tables to function properly.
For example, consider a database containing Orders and Customers tables. Each order is associated with a customer, and the Customers table contains information about each customer. If a customer places an order and deletes their account, a deletion anomaly may occur if their customer information is deleted along with their account.
This would result in the loss of important information about the customer that is required for the Orders table to function properly.
It is important to design databases with data integrity in mind to prevent deletion anomalies, including establishing relationships between tables and enforcing referential integrity constraints.
This helps ensure that deleting data from one table does not result in the unintended loss of information from other tables in the database.
Example: Database Normalization
Before Normalization, the data is stored in a single table with redundant information. After Normalization, the data is separated into multiple tables to eliminate redundancy and improve data consistency.
Let’s consider a table that stores information about customers and their orders. Here’s what the table could look like before normalization:
| CustomerID | CustomerName | CustomerAddress | OrderID | OrderDate | OrderAmount |
|---|---|---|---|---|---|
| 1 | Robert Smith | 123 Main St. | 1 | 2023-01-01 | $100.00 |
| 2 | Maria Doe | 456 Elm St. | 2 | 2023-01-02 | $200.00 |
| 1 | Robert Smith | 123 Main St. | 3 | 2023-01-03 | $50.00 |
| 3 | Bob Johnson | 789 Oak St. | 4 | 2023-01-04 | $75.00 |
As you can see, there is some redundancy in the table. For example, Robert Smith’s information is repeated twice, leading to data inconsistencies and making it more challenging to update the information in the table.
Now, let’s normalize this table. First, we can create a separate table for customers and their information:
Here is an example of how the data in the tables might look after normalization:
Table 1: Customers
| CustomerID | CustomerName | CustomerAddress |
|---|---|---|
| 1 | Robert Smith | 123 Main St. |
| 2 | Maria Doe | 456 Elm St. |
| 3 | Bob Johnson | 789 Oak St. |
And then, we can create a separate table for orders and their information:
Table 2: Orders
| OrderID | OrderDate | OrderAmount | CustomerID |
|---|---|---|---|
| 1 | 2023-01-01 | $100.00 | 1 |
| 2 | 2023-01-01 | $200.00 | 2 |
| 3 | 2023-01-01 | $50.00 | 1 |
| 4 | 2023-01-01 | $75.00 | 3 |
In the above example, the Customers table contains unique customer information, while the Orders table contains information specific to each order, including the customer who placed the order.
Thus, Normalization eliminates redundancy and improves data consistency by separating the data into multiple tables and establishing relationships between them.
First Normal Form (1NF)
First Normal Form (1NF) is a fundamental concept in database normalization that helps eliminate data redundancy and ensure data integrity. The primary goal of 1NF is to eliminate repeating groups and ensure that each field in a table contains a single atomic value.
A table that conforms to 1NF must meet the following requirements:
- Atomic values: Every cell in a table must contain a single, atomic value.
- Unique column names: Each column in a table must have a unique name.
- Same data type: Entries in a column must be of the same data type.
- Ordered rows: Each row in a table must be uniquely identifiable, such as through a primary key.
- The order in which data is stored does not matter.
Example: First Normal Form (1NF)
To convert the Customers table to 1NF, we need to ensure that each attribute has a single value, and there are no repeating groups of attributes. Here is an example of how we can achieve 1NF for the Customers table:
Original Customers table:
| CustomerID | CustomerName | CustomerAddress |
|---|---|---|
| 1 | Robert Smith | 123 Main St. |
| 2 | Maria Doe | 456 Elm St. |
| 3 | Bob Johnson | 789 Oak St. |
1NF Customers table:
| CustomerID | FirstName | LastName | StreetNumber | StreetName | City | State | ZipCode |
|---|---|---|---|---|---|---|---|
| 1 | Robert | Smith | 123 | Main St. | Anytown | CA | 12345 |
| 2 | Maria | Doe | 456 | Elm St. | Anytown | CA | 12345 |
| 3 | Bob | Johnson | 789 | Oak St. | Anytown | CA | 12345 |
Second Normal Form (2NF)
The Second Normal Form (2NF) is achieved when a table is in 1NF, and all the non-key attributes fully depend on the primary key. This means that every non-key attribute must depend on the whole primary key and not just a part of it. If there are any partial dependencies in a table, it is not in 2NF.
- A table must first meet all requirements of the First Normal Form (1NF) to satisfy the Second Normal Form,
- Any data subsets that are common to multiple rows in a table should be separated and placed into different tables.
- These new tables should establish relationships with their parent tables by using foreign keys.
To explain this further, let’s use the example tables from the previous question:
| CustomerID | FirstName | LastName | StreetNumber | StreetName | City | State | ZipCode |
|---|---|---|---|---|---|---|---|
| 1 | Robert | Smith | 123 | Main St. | Anytown | CA | 12345 |
| 2 | Maria | Doe | 456 | Elm St. | Anytown | CA | 12345 |
| 3 | Bob | Johnson | 789 | Oak St. | Anytown | CA | 12345 |
| OrderID | OrderDate | OrderAmount | CustomerID |
|---|---|---|---|
| 1 | 2023-01-01 | $100.00 | 1 |
| 2 | 2023-01-01 | $200.00 | 2 |
| 3 | 2023-01-01 | $50.00 | 1 |
| 4 | 2023-01-01 | $75.00 | 3 |
Explanation:
- The table is already in 1NF, with no repeating groups or columns.
- The primary key for the Orders table is the OrderID column, and CustomerID is a foreign key that references the Customer table’s primary key.
- In the Customer table, the columns are directly related to the primary key CustomerID.
- In the Orders table, the columns are directly related to the primary key OrderID, not the foreign key CustomerID.
Here, we have eliminated the partial dependency by creating two tables and establishing a relationship between them using the CustomerID column as a foreign key in the orders table.
By splitting the table, we have eliminated the data redundancy that occurs when data is repeated in a table. This ensures that each table contains only unique data, making it easy to update, maintain and query the database.
In summary, the Second Normal Form (2NF) ensures that all non-key attributes in a table depend on the entire primary key, not just part of it. By eliminating partial dependencies, we can reduce data redundancy and improve data integrity in our database.
Third Normal Form (3NF)
The Third Normal Form (3NF) requires that a table must be in Second Normal Form (2NF) and should not have any transitive dependencies. Transitive dependency means when a non-key column is determined by another non-key column, which is determined by the primary key. This can cause data redundancy and inconsistency.
In simpler terms, a table is in 3NF if it has been normalized to the point where each non-key column is only dependent on the primary key of the table.
The rules for Third Normal Form (3NF) are as follows:
- The table must already be in 2NF.
- Every non-key column must be directly dependent on the primary key.
- There should be no transitive dependency between non-key columns.
Example: Third Normal Form (3NF)
Here, We will understand transitive dependency using our existing tables.
Let’s take the example of the Customers table we have been using:
| CustomerID | CustomerName | CustomerAddress |
|---|---|---|
| 1 | Robert Smith | 123 Main St. |
| 2 | Maria Doe | 456 Elm St. |
| 3 | Bob Johnson | 789 Oak St. |
Suppose we add a new column CustomerState to the table to track the state where the customer lives:
| CustomerID | CustomerName | CustomerAddress | CustomerState |
|---|---|---|---|
| 1 | Robert Smith | 123 Main St. | New York |
| 2 | Maria Doe | 456 Elm St. | California |
| 3 | Bob Johnson | 789 Oak St. | New York |
Here, we have introduced a transitive dependency between CustomerState and CustomerID through CustomerAddress. That is, CustomerState is determined by CustomerAddress, which is determined by CustomerID.
This can cause data redundancy and inconsistency because if the CustomerAddress for a customer changes, then we need to update the CustomerState for that customer as well. This can lead to inconsistencies if we forget to update one of the fields.
To remove this transitive dependency, we can split the Customer table into two separate tables, one for the customers and one for their addresses:
So finally, we will now have a total of three tables:
- Customers
- Addresses
- Orders
Table 1: Customers
| CustomerID | CustomerName |
|---|---|
| 1 | Robert Smith |
| 2 | Maria Doe |
| 3 | Bob Johnson |
Table 2: Addresses
| CustomerID | CustomerAddress | CustomerState |
|---|---|---|
| 1 | 123 Main St. | New York |
| 2 | 456 Elm St. | California |
| 3 | 789 Oak St. | New York |
Here, the CustomerID column is the primary key for the Customers table and a foreign key in the Addresses table. This way, we can avoid transitive dependency and store the data more efficiently and consistently.
Table 3: Orders
| OrderID | OrderDate | OrderAmount | CustomerID |
|---|---|---|---|
| 1 | 2023-01-01 | $100.00 | 1 |
| 2 | 2023-01-01 | $200.00 | 2 |
| 3 | 2023-01-01 | $50.00 | 1 |
| 4 | 2023-01-01 | $75.00 | 3 |
In conclusion, the Third Normal Form (3NF) helps to remove the transitive dependencies and makes the table more consistent and reliable. It is important to note that normalization does not guarantee performance optimization but helps maintain data consistency, which can lead to better performance.
Boyce and Codd Normal Form (BCNF or 3.5NF)
Boyce and Codd Normal Form (BCNF) is a higher level of database normalization, which eliminates more complex types of data anomalies that cannot be resolved by a third normal form (3NF). BCNF is named after R. Boyce and E.F. Codd, who proposed this normal Form in the 1970s.
Boyce-Codd Normal Form (BCNF) is a higher level of database normalization beyond 3NF. It is based on the functional dependencies within a table and ensures that all attributes depend only on the candidate keys.
The rules for BCNF are as follows:
- Meet all the requirements of the third normal form (3NF).
- Every determinant in the table must be a candidate key.
- No non-prime attribute should be functionally dependent on any proper subset of a candidate key.
In simpler terms, BCNF states that for a table to be in BCNF:
- Every non-trivial functional dependency should be a dependency on a superkey.
- Every candidate key in the table should have a non-trivial functional dependency on all the attributes in the table.
Candidate key
A candidate key refers to one or a combination of columns in a database table that can be used as a unique identifier. Having more than one candidate key in a single table is possible, and each can be considered a primary key.
primary key
The primary key is the unique identifier for a table, and it’s used to enforce data integrity by ensuring that each record in the table is uniquely identified. The primary key must be unique, not null, and can’t be changed or updated once set. Only one candidate key can be designated as the primary key.
To illustrate the concept of BCNF, consider the following table:
Here’s how the OrderDetails table may look like before normalizing it to BCNF:
Table: OrderDetails
| OrderID | ProductID | ProductName | ProductDescription | SupplierID | SupplierName | SupplierCountry | Quantity | Price |
|---|---|---|---|---|---|---|---|---|
| 1 | 1001 | iPhone 12 | Smartphone | 1 | Apple | USA | 2 | $2400 |
| 1 | 1002 | AirPods Pro | Wireless Earphones | 1 | Apple | USA | 1 | $249 |
| 2 | 1003 | Galaxy S21 | Smartphone | 2 | Samsung | South Korea | 1 | $799 |
| 2 | 1004 | Galaxy Buds | Wireless Earbuds | 2 | Samsung | South Korea | 2 | $199 |
| 3 | 1001 | iPhone 12 | Smartphone | 1 | Apple | USA | 1 | $1200 |
| 3 | 1005 | MacBook Pro | Laptop | 1 | Apple | USA | 1 | $1500 |
After normalizing OrderDetails to BCNF, It’s split into following tables:
Table: Products
| ProductID | ProductName | ProductDescription |
|---|---|---|
| 1001 | iPhone 12 | Smartphone |
| 1002 | AirPods Pro | Wireless Earphones |
| 1003 | Galaxy S21 | Smartphone |
| 1004 | Galaxy Buds | Wireless Earbuds |
| 1005 | MacBook Pro 2021 | Laptop |
Primary Key: ProductID
Table: Suppliers
| SupplierID | SupplierName | SupplierCountry |
|---|---|---|
| 1 | Apple | USA |
| 2 | Samsung | South Korea |
Primary Key: SupplierID
Table: OrderDetails
| OrderID | ProductID | Quantity | Price |
|---|---|---|---|
| 1 | 1001 | 2 | $1200 |
| 1 | 1002 | 1 | $249 |
| 2 | 1003 | 1 | $799 |
| 2 | 1004 | 2 | $199 |
| 3 | 1001 | 1 | $600 |
| 3 | 1005 | 1 | $1500 |
- Candidate key: (OrderID, ProductID)
Table: ProductSupplier
| ProductID | SupplierID |
|---|---|
| 1001 | 1 |
| 1002 | 1 |
| 1003 | 2 |
| 1004 | 2 |
| 1005 | 1 |
Candidate Key: (ProductID, SupplierID)
Table: OrderSupplier
| OrderID | SupplierID |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 1 |
Candidate Key: (OrderID, SupplierID)
Fourth Normal Form (4NF)
The Fourth Normal Form (4NF) is a level of database normalization that reduces data redundancy and improves data integrity. It deals with multi-valued dependencies, which occur when a table contains two or more independent multi-valued facts about an entity.
In simpler terms, 4NF helps to break down complex information into smaller, more manageable pieces, ensuring that each piece is only stored in one place.
The rules of the Fourth Normal Form (4NF) are as follows:
- The table must already be in Third Normal Form (3NF)
- There must be no non-trivial multi-valued dependencies between the candidate keys of the table
Example: 4NF
To illustrate this, let’s consider the following example. Suppose we have a table called “Books” with columns for “Book ID”, “Title”, “Author”, and “Genres”. In this case, we have a multi-valued dependency because a single book can have multiple genres, and each genre can be associated with multiple books.
To apply 4NF, we need to create two tables:
- Genres and
- Books
The “Genres” table contains a list of book genres, each identified by a unique “GenreID” column. The “Books” table contains information about individual books, including a primary key, “BookID”, the book title and author name, and a foreign key “GenreID” that references the “Genres” table.
After 4NF, the “Books” table would look like this:
| BookID | BookTitle | AuthorName | GenreID |
|---|---|---|---|
| 1 | The Catcher in the Rye | J.D. Salinger | 1 |
| 2 | 1984 | George Orwell | 3 |
| 3 | The Da Vinci Code | Dan Brown | 4 |
| 4 | Pride and Prejudice | Jane Austen | 5 |
| 5 | The Great Gatsby | F. Scott Fitzgerald | 1 |
| 6 | The Hobbit | J.R.R. Tolkien | 3 |
| 7 | The Hunger Games | Suzanne Collins | 3 |
| 8 | The Girl with the Dragon Tattoo | Stieg Larsson | 4 |
After applying 4NF, the “Genres” table would look like this:
| GenreID | GenreName |
|---|---|
| 1 | Fiction |
| 2 | Non-Fiction |
| 3 | Science Fiction |
| 4 | Mystery |
| 5 | Romance |
How does data normalization improve the performance of relational databases?
Data normalization improves the performance of relational databases in the following ways:
- Reduces data redundancy: By eliminating data redundancy, normalization reduces the amount of data stored in the database, which reduces the storage requirements and can lead to faster queries.
- Improves data consistency: Normalization helps ensure that data is consistent by eliminating update anomalies, which can cause inconsistencies when data is updated in one place but not in others.
- Reduces the number of null values: By organizing data into separate tables, normalization reduces the number of null values in the database, improving query performance.
- Simplifies queries: Normalization simplifies queries by reducing the need to join multiple tables together to obtain data.
- Enables better indexing: Normalized tables can be indexed more effectively, improving query performance.
- Facilitates database maintenance: Normalization makes it easier to maintain the database by reducing the need for a complex update and delete operations.
FAQs:
Q: What is Database Normalization?
Database normalization is the process of organizing a database to reduce redundancy and dependency among tables. It aims to improve the integrity and efficiency of a database by reducing data duplication.
Q: Why is database normalization necessary?
Database Normalization is important because it helps to eliminate data redundancy and dependency in a database. Doing so ensures that a database is consistent and that data is stored in a way that is easy to access and maintain.
Q: What are the different normal forms in database normalization?
There are several Normal Forms in database normalization, including the
First Normal Form (1NF), Second Normal Form (2NF), Third Normal Form (3NF), Boyce-Codd Normal Form (BCNF), and Fourth Normal Form (4NF).
Q: What is the purpose of each normal form?
The purpose of each normal form is to eliminate a specific type of data redundancy or dependency.
For example, 1NF eliminates repeating groups, 2NF eliminates partial dependencies, 3NF eliminates transitive dependencies, BCNF eliminates certain types of functional dependencies, and 4NF eliminates multi-valued dependencies.
Q: How does normalization improve database performance?
Normalization improves database performance by reducing the amount of data duplication and inconsistency, making it easier to access and maintain data. This results in faster queries, reduced storage space, and improved database integrity.
Q: Is normalization always necessary?
Normalization is not always necessary, and it depends on the specific requirements and constraints of the database.
In some cases, it may be acceptable to have redundant or dependent data if it improves performance or meets other business requirements.
References: WikiPedia-Database Normalization
You might want to read this too:
- Types of Joins in SQL Server
- Having VS Where Clause in SQL
- SQL EXISTS – Exploring EXISTS Operator in SQL Server
- Like operator in SQL
- Different ways to delete duplicate rows in SQL Server
- COALESCE in SQL With Examples and Use Cases for Handling NULL Values
- SQL Server CONVERT Function: How to Convert Data Types in SQL Server
- Delete vs Truncate vs Drop in SQL Server
- SQL Server TRY_CAST() Function – Understanding TRY_CAST() in SQL with [Examples]
- SQL Server Try Catch: Error Handling in SQL Server With [Examples]

- C# 12 New Features in 2025: What’s New with .NET 8 - April 11, 2025
- Difference Between WCF and Web API with Examples: A Comprehensive Guide - March 27, 2025
- PUT vs PATCH vs POST in REST API: Key Differences Explained With Examples - March 23, 2025